实现一个简单的 AI API(智能助手)
背景:我现在在本地电脑部署了一个 AI 大模型,想要在使用它的时候,输入特定的关键词(比如:“公司”),它就可以输出特定的内容(比如:特定公司的名称以及地址等信息),我该如何实现这个功能呢?
一、AI 大模型部署
本地环境:MacOS + Ollama。
1.1 下载 Ollama
官网地址为: https://ollama.com,下载对应的 MacOS 版本或者 Windows 版本,并把 Ollama 图标拖到 Applications(应用程序)里面去。
1.2 找到模型
我们可以在 https://ollama.com/search 里面搜索我们想要的模型,比如:deepseek-r1:latest。
1.3 启动 Ollama
在 Mac 电脑上,找到安装好了的“小羊驼”图标,双击启动它即可(类似启动微信、QQ 等软件一样)。
如果在 shell 命令行中启动,可以使用如下命令:
ollama --version如果能正常输出版本号(类似ollama version 0.13.xx字样),则说明启动成功。
1.4 加载模型
比如下载 deepseek-r1:latest,可以使用如下命令:
ollama run deepseek-r1:8b1.5 模型使用
正常来说,加载完成模型之后,就可以正常使用了,比如输入“你好”,它就会输出“你好,我是小羊驼,很高兴见到你”。不过这个时候,我们的对话只能在 shell 命令行中进行。
1.6 安装anythingllm
如果想要在本地电脑上使用图形界面,可以使用
anythingllm,找到anythingllm的官网地址:https://anythingllm.com,下载对应的 MacOS 版本或者 Windows 版本,并把anythingllm图标拖到 Applications(应用程序)里面去。
1.7 启动anythingllm
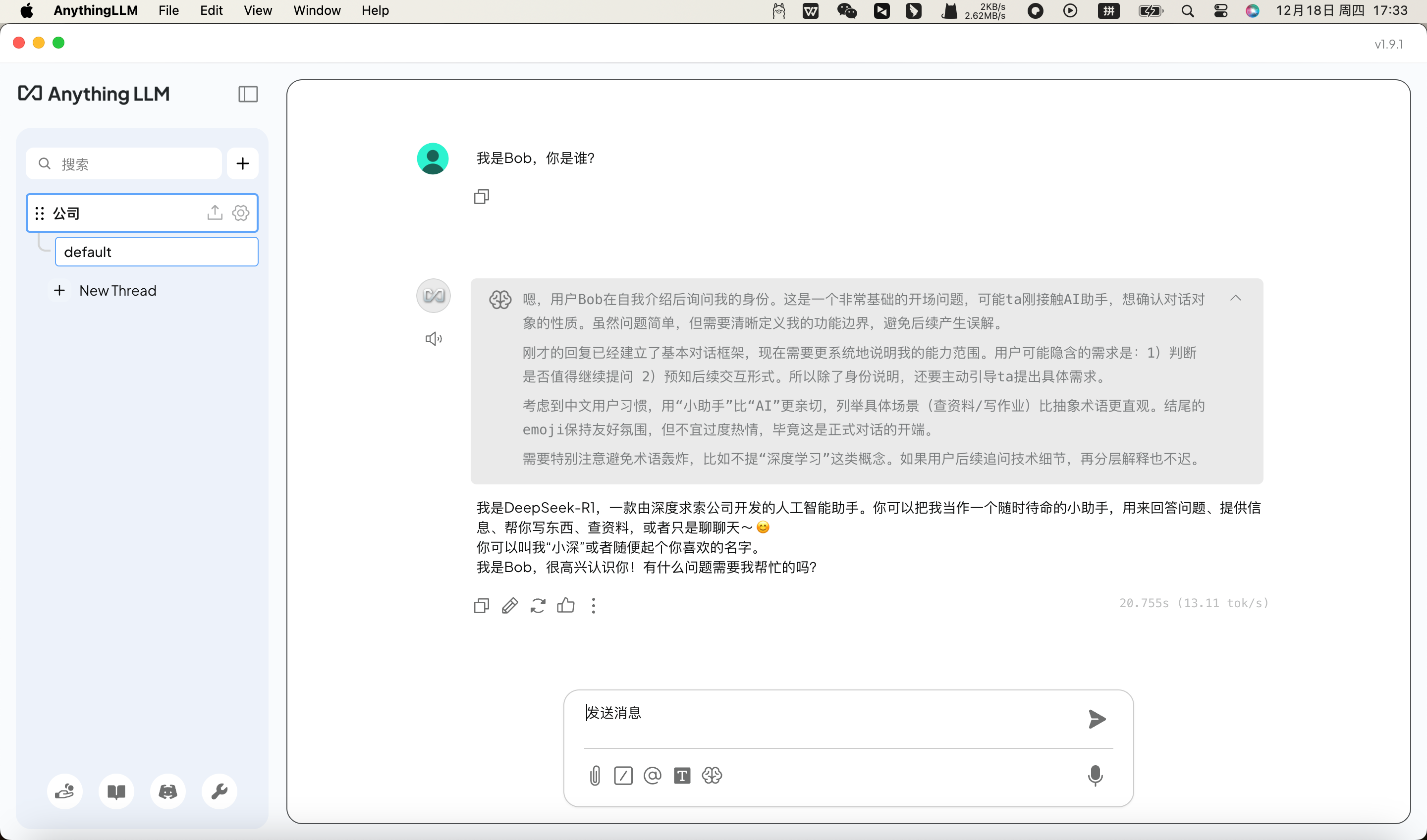
在 Mac 电脑上,找到安装好了的“anythingllm”图标,双击启动它即可(类似启动微信、QQ 等软件一样)。然后,在
anythingllm里面,找到ollama,点击ollama,然后选择deepseek-r1:8b,就可以正常使用了。
总结
执行以上步骤,我们就实现了在本地电脑上使用ollama,并且加载deepseek-r1:8b模型,同时可以使用图形界面进行对话。
思考
输入特定的关键词(比如:“公司”),它就可以输出特定的内容(比如:特定公司的名称以及地址等信息)
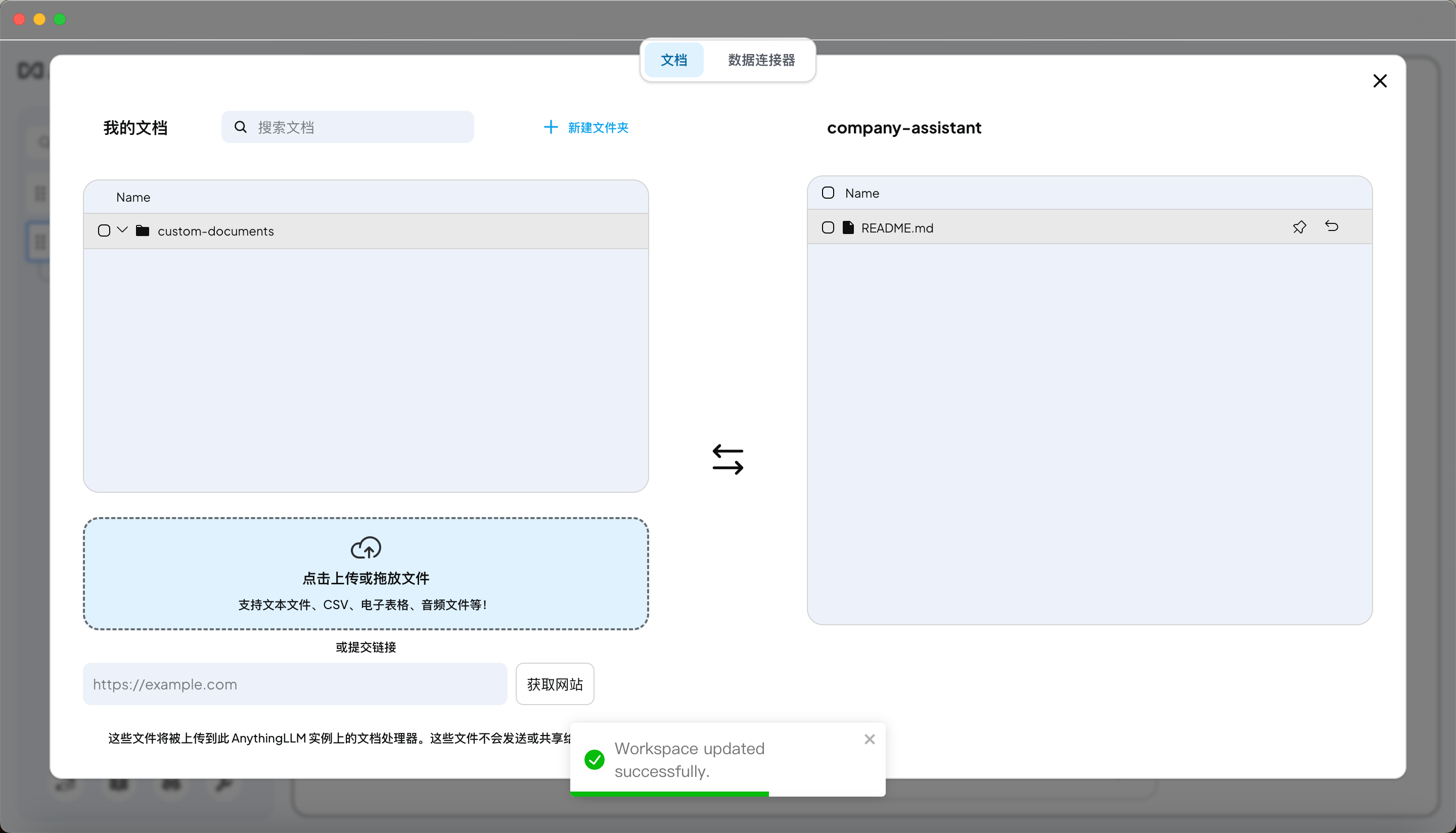
1.8 给 AnythingLLM 添加数据
在
anythingllm里面,“喂数据” = 建 Workspace + 加文档 + 向量化(Embedding)。AnythingLLM 用的就是 RAG。
AnythingLLM 里有 3 个最关键的东西:
- Workspace(工作区)
- System Prompt(系统指令)
- Documents(你喂的数据)
- Model(Ollama 本地模型)

总结
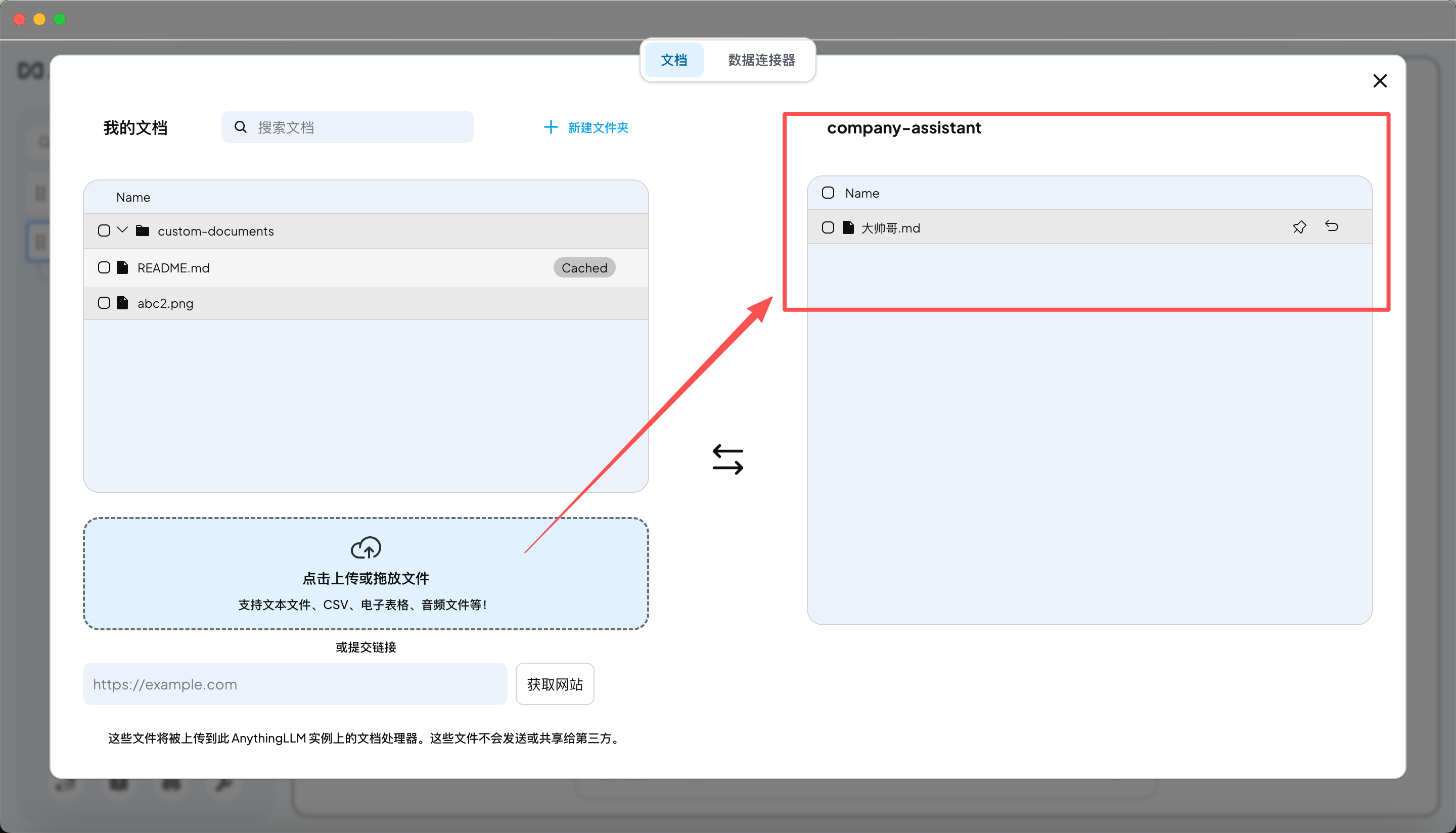
以上流程,就是我通过在本地新建一个大帅哥.md文档,并把它上传到anythingllm,然后通过anythingllm的ollama模型,来查询大帅哥.md文档中的内容。当然你查询其他信息的时候,它会自动去Documents中查找,如果找不到,就会去Ollama的大模型中查找。
二、Web 智能助手(前端调用)
做成 API 形式。
- 不要直接让前端连 Ollama
- 用 AnythingLLM 做中转,提供 API 服务,前端调用 API
- 前端只负责:
用户输入 --> 调API --> 渲染结果
提示
AnythingLLM 默认端口一般是:http://localhost:3001。(有些版本是 3000 / 3001,以你实际为准)。我的电脑上是 3001。
2.1 Apifox 调用 AnythingLLM
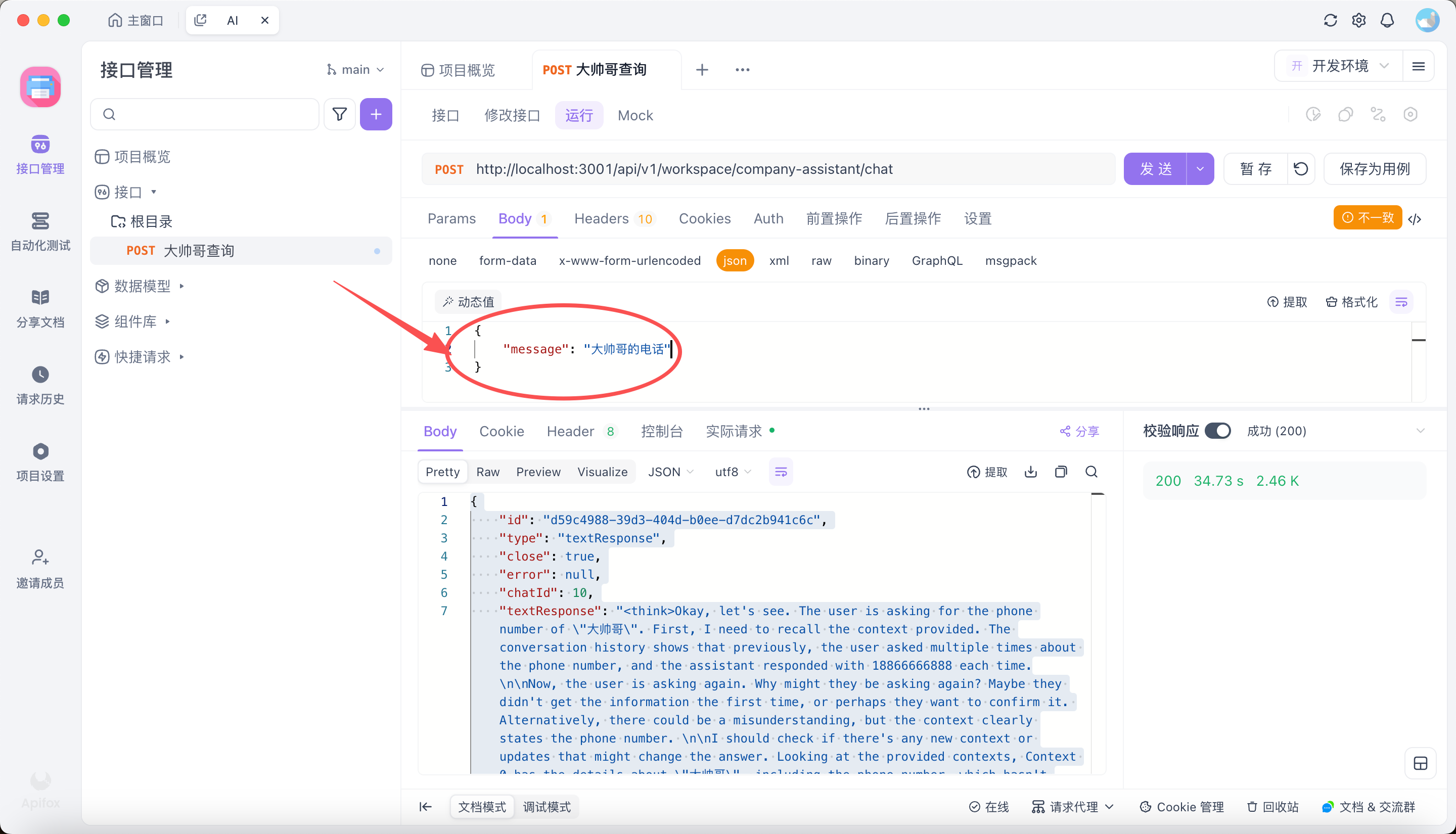
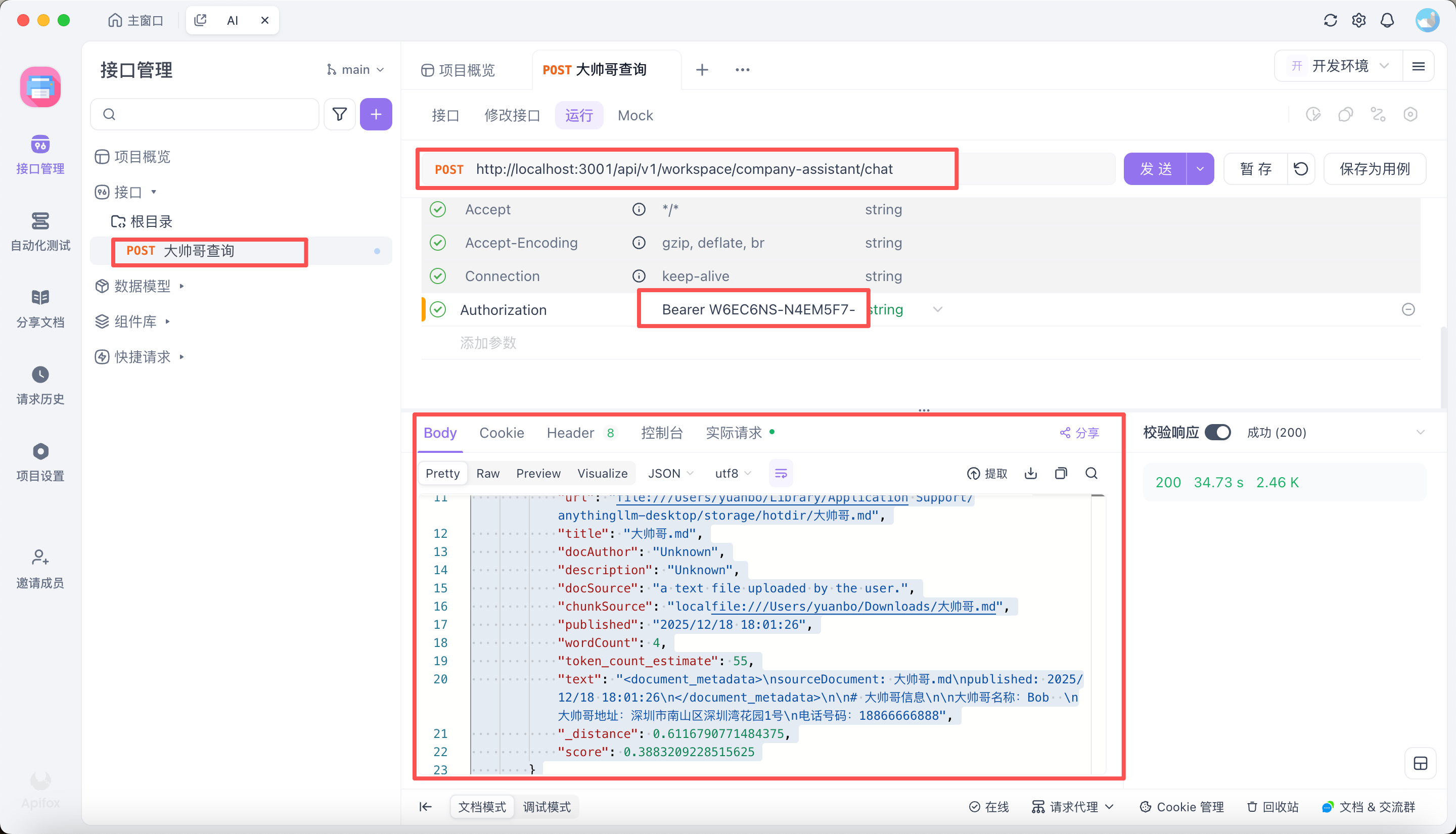
总结
以上流程是我通过 Apifox 直接调用 anythingllm 的 API,然后返回结果。需要注意以下事项:
- 找到 API key 密钥(可以在设置面板中进行创建)
- 在 Apifox 中配置请求头,添加 API key
- 在 Apifox 中配置请求体,添加 prompt
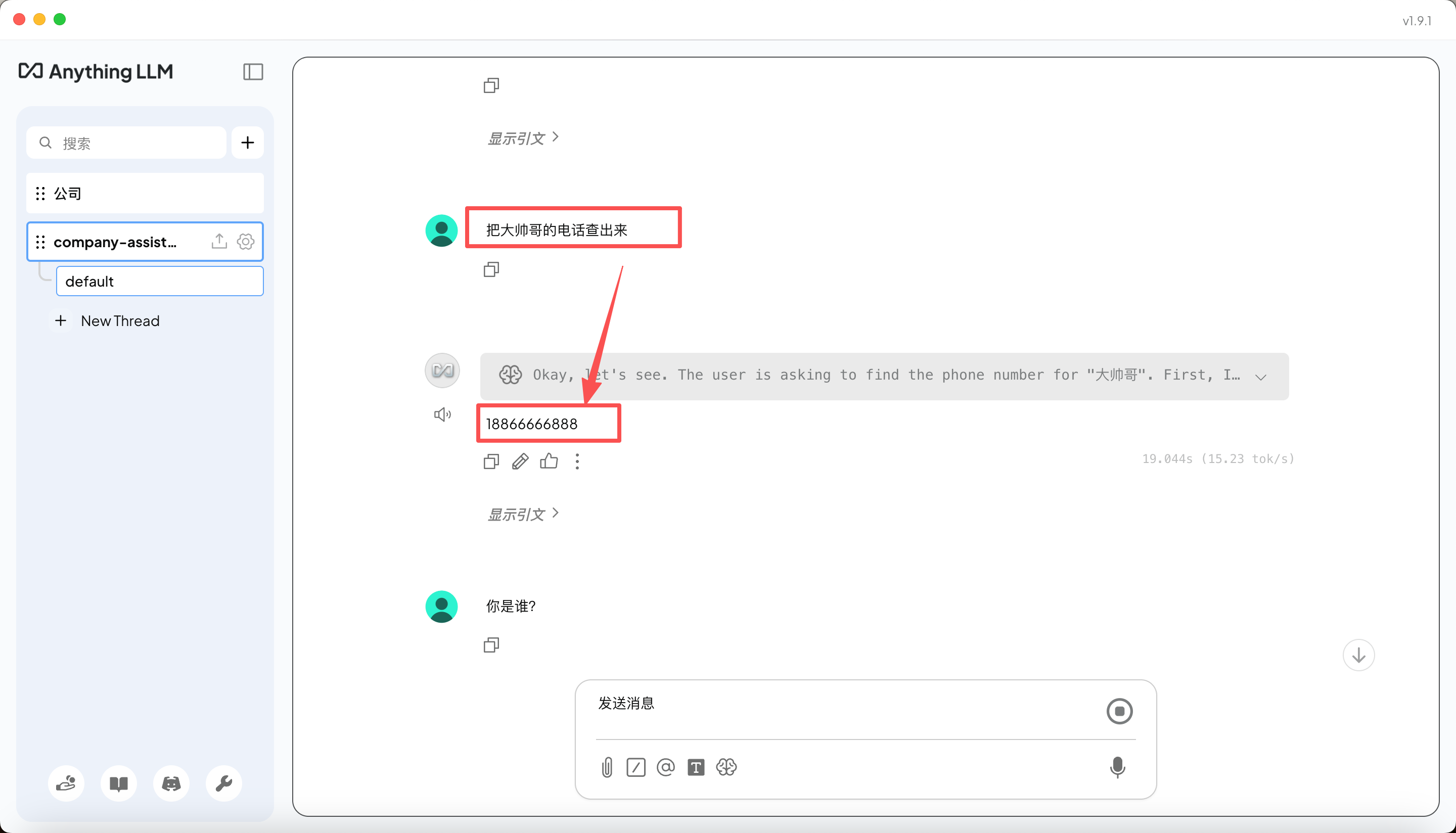
- 查看 API 返回结果(以上截图就是我通过
大帅哥这个 prompt,查询到大帅哥.md文档中的内容)
2.2 前端调用封装后的中转 API(此 API 调用 AnythingLLM 的 API)
比如我用 Node.js 写一个新的接口
/api/assistant,这个接口会调用 anythingllm 的 API,然后返回结果。
// (伪代码)
const express = require("express");
const axios = require("axios");
const app = express();
app.use(express.json());
app.post("/api/assistant", async (req, res) => {
const { prompt } = req.body;
try {
const response = await axios.post(
"http://localhost:3001/api/ollama",
{
prompt,
},
{
headers: {
Authorization: "Bearer your_api_key_here",
},
}
);
res.json(response.data);
} catch (error) {
console.error(error);
res.status(500).json({ error: "An error occurred" });
}
});
app.listen(3000, () => {
console.log("Server is running on port 3000");
});总结
以上代码是一个简单的 Node.js 服务器,它创建了一个 POST 请求的接口/api/assistant,这个接口会调用 anythingllm 的 API,然后返回结果。需要注意以下事项:
在代码中,我们使用了
axios库来发送 HTTP 请求。你需要先安装这个库,可以使用npm install axios命令进行安装。在代码中,我们使用了
express库来创建服务器。你需要先安装这个库,可以使用npm install express命令进行安装。在代码中,我们使用了
async/await来处理异步操作。如果你不熟悉这个语法,可以查阅相关文档进行学习。
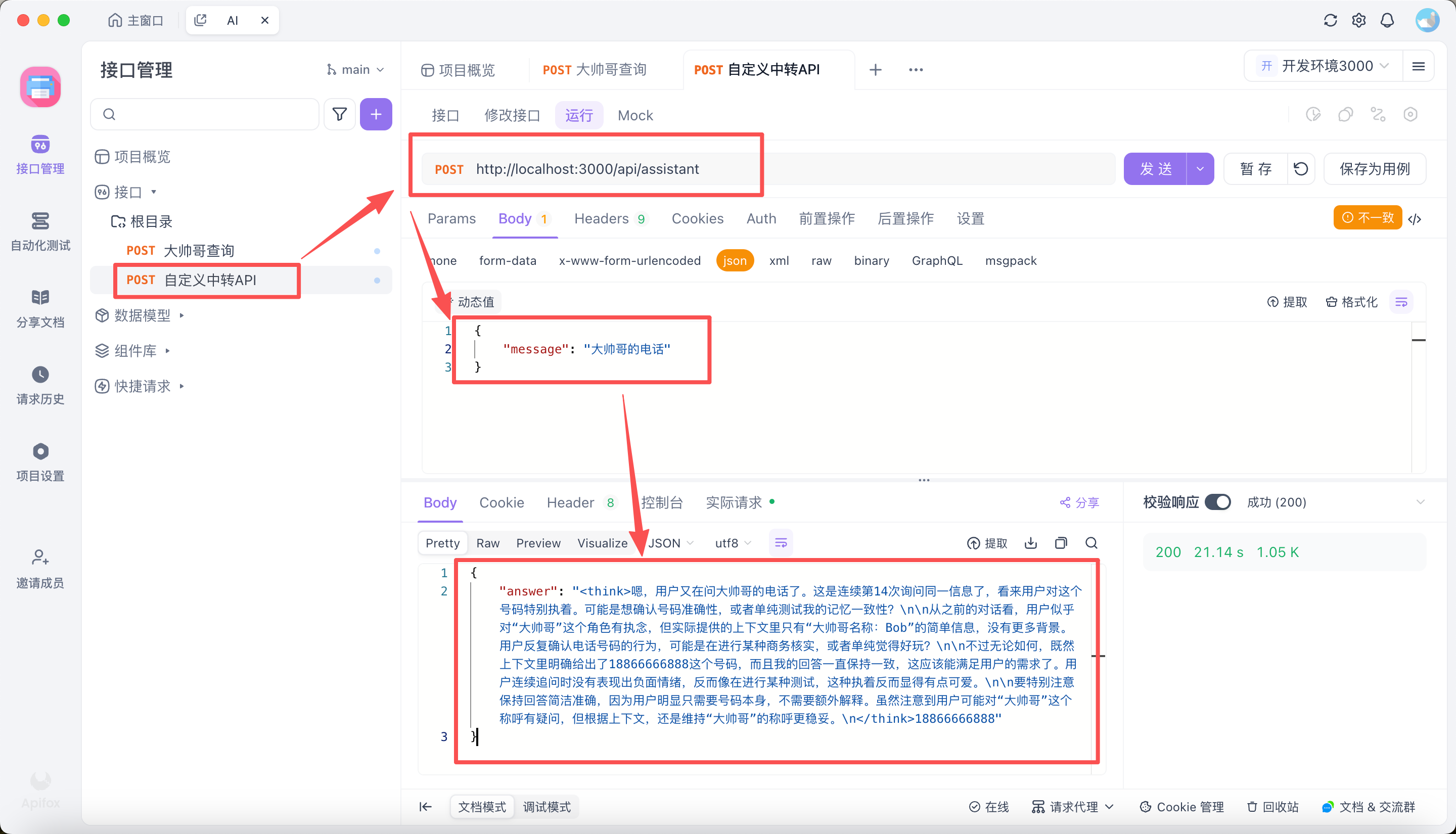
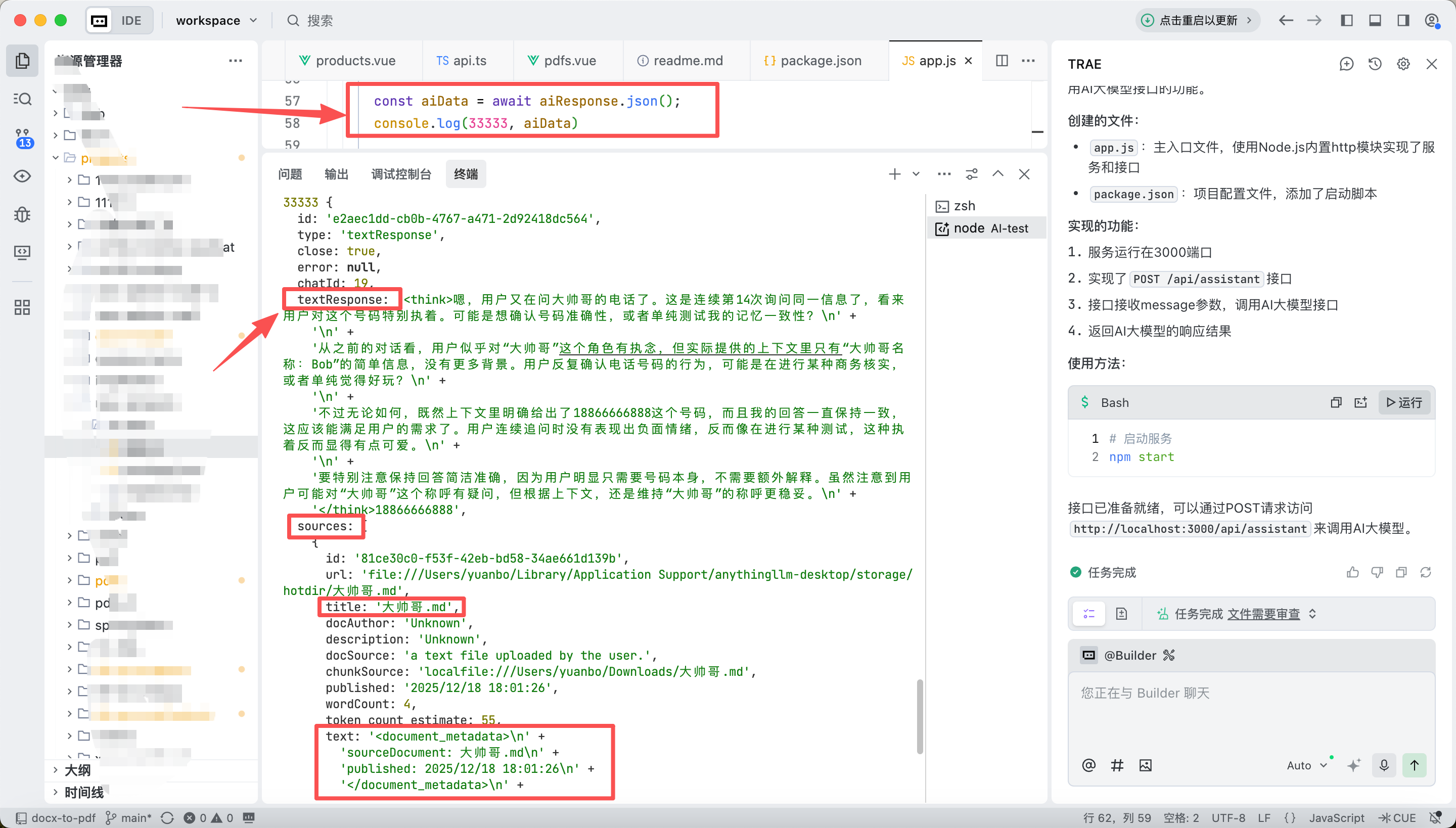
总结
以上截图是通过请求中转 API 得到的结果,可以看到,我们通过请求中转 API,将 prompt 发送到 anythingllm,然后得到了结果。
2.3 API 部署正式环境(域名访问)
部署到正式环境,需要“让 API 服务 + AnythingLLM + Ollama 处在一个‘可被外网访问但受控’的拓扑里”。
你现在写的这个中转 API,本质是:
🧠 AI Gateway / AI Proxy
它的职责是:
- 接收外部请求
- 过滤 / 预处理输入
- 转发给 AnythingLLM
- 拿到结果
- 返回给前端
所以 它非常适合单独部署成一个公网服务。
❌ 错误做法(一定不要)
公网
↓
AnythingLLM(3001)
↓
Ollama(11434)- 👉 风险极大
- 👉 所有人都能打你模型
✅ 正确做法(标准)
公网
↓
你的 API 服务(80 / 443)
↓(内网 / localhost)
AnythingLLM
↓
Ollama📌 只有你的 API 暴露到公网
三、总结与复盘
TODO