HTML
HTML(超文本标记语言) 是用于创建网页和应用界面的标记语言,其原理基于内容的语义化结构定义和浏览器的解析渲染能力。
HTML
HTML 更多的是一种规范,编码的规范,如果不按照规范来,可能会有意想不到的结果。它是给浏览器看的,浏览器会根据规范来渲染页面。
1. HTML 基础结构
- 文档类型声明:
<!DOCTYPE html>文档类型声明用于指定 HTML 文档所遵循的标准或规范。DOCTYPE 的目的是让浏览器知道应该如何解析 HTML 文档。
HTML5 标准(2014 年发布)大大简化了 DOCTYPE 声明:<!DOCTYPE html>。- 文档类型声明的主要作用是告知浏览器该页面应以“标准模式”进行渲染。没有 DOCTYPE 声明,浏览器可能会进入“怪异模式”(Quirks Mode),这会导致页面在不同浏览器中的显示不一致,特别是旧版浏览器。
- 作用:确保网页在不同浏览器中的一致性和准确性。
- 根元素:
<html><html>元素是 HTML 文档的根元素,所有 HTML 元素都应当位于<html>标签内。它包裹着整个文档内容,包括头部(<head>)和主体(<body>)注意:如果 HTML 元素不写在
<html>标签内,现在浏览器也会将其纳入到<html>标签内(但是多余的<html>和<body>只能显示其内部的内容而不能显示标签,也就是说一个页面中不能存在多个<html>或<body>)。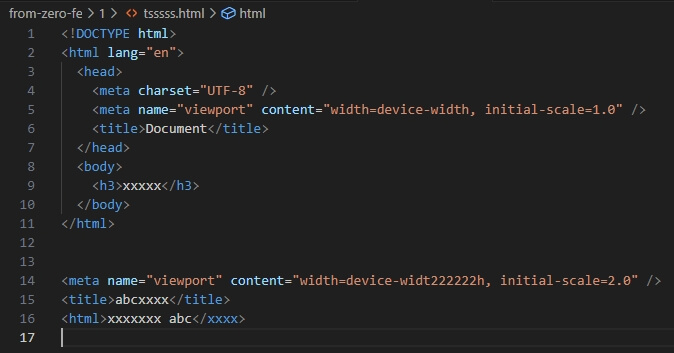

- 文档头部:
<head><head>是 HTML 文档的元数据部分,通常不直接呈现在页面内容中,但它包含了与文档相关的关键信息,例如标题、字符编码、外部资源的链接等。所有用于页面的元信息和外部文件引用都放在<head>中。<title>:文档标题<meta>:字符集、描述、关键词等<link>:外部资源链接(如 CSS)<script>:嵌入或外部 JavaScript- defer 和 async 属性:
- defer:表示脚本会延迟到 HTML 文档完全解析后再执行。
- async:表示脚本在下载后会立即执行,不会等待文档的解析。
- defer 和 async 属性:
<style>:内联样式
- 文档主体:
<body>
2. 文本结构元素
- 标题:
<h1> - <h6>- 为什么不同标题元素自带样式效果?
<h1>到<h6>标签是HTML中定义标题的元素,它们自带样式效果的原因主要来自于HTML的语义化 和 浏览器的默认样式设置。- 浏览器的 默认样式 是由浏览器自带的一个 用户代理样式表(User Agent Stylesheet)定义的。
- 每个浏览器都内置了一个用户代理样式表,它包含了浏览器对所有 HTML 元素的默认样式定义。为了确保网页即使没有任何外部样式(CSS),也能够以某种合理的方式展示内容而应用的默认样式。
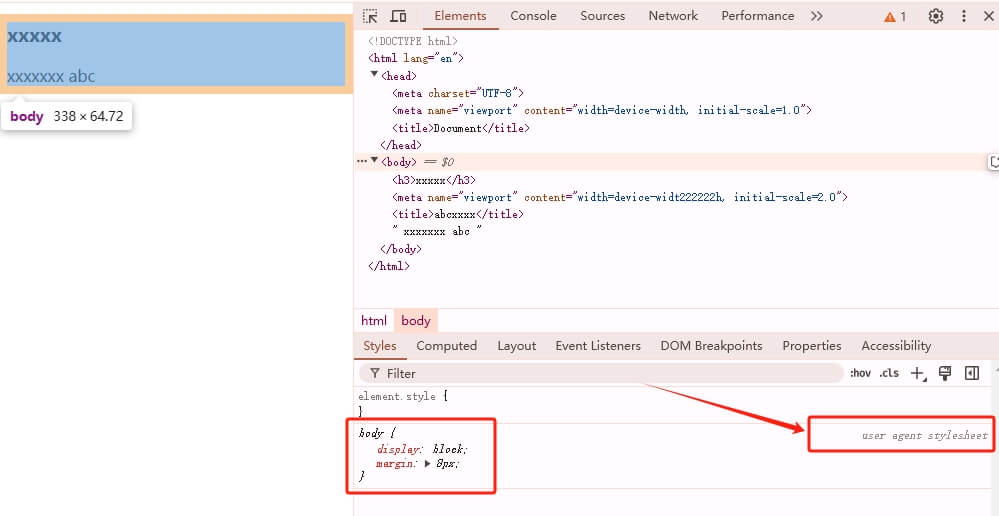
- 如何查看
- 对于 Chrome/Chromium:
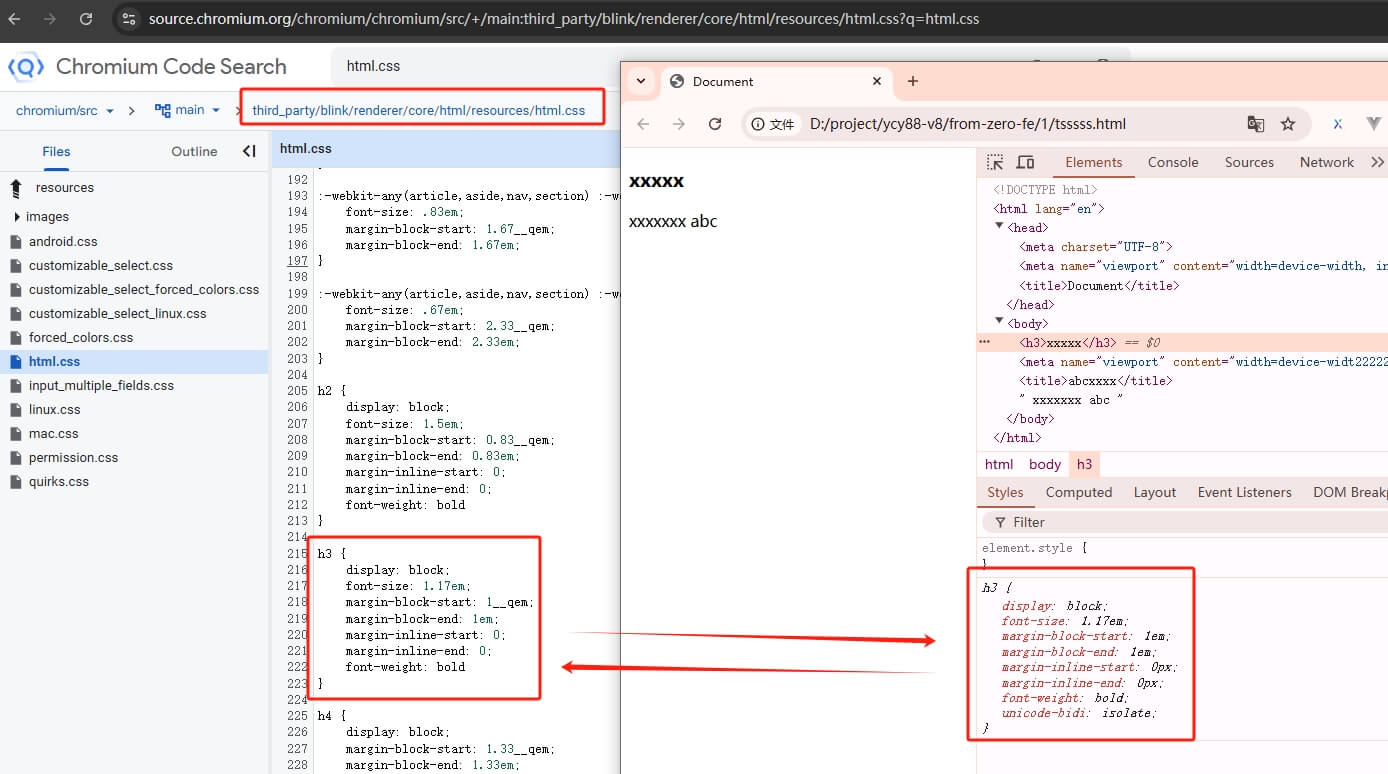
- Chrome 的用户代理样式表可以在 Chromium 项目代码中找到:
- 路径:https://source.chromium.org/,搜索关键字 html.css 或 ua.css。
- 示例文件:
- html.css:主要定义 HTML 元素的默认样式。
- quirks.css:处理旧版 HTML 的兼容性样式。
- Chrome 的用户代理样式表可以在 Chromium 项目代码中找到:
- 直接查找 Chromium 的内置样式表文件:在本地找到这些默认样式文件
- TODO
- 对于 Chrome/Chromium:
- 为什么不同标题元素自带样式效果?
- 段落:
<p> - 文本格式化标签:
- 强调:
<em>,<strong> - 删除线:
<del>,<ins> - 代码:
<code>,<pre>,<samp> - 引用:
<blockquote>,<q> - 换行符:
<br>
- 强调:
- 列表:
- 无序列表:
<ul>,<li> - 有序列表:
<ol>,<li> - 定义列表:
<dl>,<dt>,<dd>
- 无序列表:
浏览器是如何识别这些不同的标签元素的?
解析阶段:
- 读取 HTML 文本流:
- 浏览器从网络、缓存或本地文件读取 HTML 文件的文本内容。
- 分词(Tokenization):
- 将文本拆分为 HTML 元素的组成部分,例如开始标签(
<p>)、属性、内容、结束标签(</p>)。
- 将文本拆分为 HTML 元素的组成部分,例如开始标签(
- 构建 DOM 树:
- 解析的标签按结构逐层嵌套,形成一个 DOM 树。
- 每个 HTML 标签都会被转化为一个 节点对象,包含该标签的类型、属性、内容等信息。
- 特殊标签(如
<script>或<style>)会触发额外的处理流程。
- 读取 HTML 文本流:
渲染阶段:
- 匹配样式:
- 浏览器根据内置的用户代理样式表(User Agent Stylesheet)、开发者定义的 CSS 样式,来为每个 DOM 节点计算样式规则。
- 例如:
<p>会匹配默认的display: block;样式。<ul>会默认添加缩进和项目符号样式。
- 布局计算:
- 浏览器根据 DOM 和 CSS 规则计算每个元素在页面上的位置和尺寸。
- 绘制和合成:
- 元素最终被绘制到屏幕上,完成渲染。
- 匹配样式:
3. 链接和导航
- 超链接:
<a href=""> - 锚点链接:
<a name=""> - 内联链接:
<a href="#" role="button">
4. 表单元素
- 表单标签:
<form> - 输入字段:
- 文本输入:
<input type="text">,<textarea> - 选择框:
<select>,<option>,<optgroup> - 单选框和复选框:
<input type="radio">,<input type="checkbox"> - 按钮:
<button>,<input type="submit">,<input type="reset">
- 文本输入:
- 隐藏字段:
<input type="hidden"> - 日期和时间:
<input type="date">,<input type="time">,<input type="datetime-local"> - 文件上传:
<input type="file"> - 标签:
<label>
5. 媒体元素
- 图像:
<img src="" alt=""> - 视频和音频:
- 视频:
<video>,<source> - 音频:
<audio>,<source>
- 视频:
- 嵌入内容:
- iframe:
<iframe src=""> - 对象:
<object>,<embed>,<param>
- iframe:
6. 布局元素
- 块级元素:
<div>,<section>,<article>,<header>,<footer>,<main> - 行内元素:
<span>,<a>,<b>,<i> - 表格:
- 表格结构:
<table>,<tr>,<td>,<th>,<thead>,<tbody>,<tfoot> - 表格属性:
colspan,rowspan
- 表格结构:
- 栅格系统:使用
<div>和 CSS Flexbox 或 Grid 布局
块级元素和内联元素
- 块级元素:
- 默认具有 display: block; 样式。
- 独占一行,并会扩展至其父容器的宽度(除非有宽度限制)。
- 适合用来构建页面布局和容器。
- 内联元素:
- 默认具有 display: inline; 样式。
- 不会独占一行,与相邻元素排列在同一行。
- 适合用来包裹文本或小型内容。
- 注意:做
CSS3动画效果也不行。
| 特性 | 块级元素 | 内联元素 |
|---|---|---|
默认样式 display | block | inline |
| 占据行位置 | 独占一行 | 不独占一行,与相邻元素同一行排列 |
| 宽度 | 默认占满父容器宽度 | 宽度由内容决定 |
| 高度 | 可通过 CSS 控制 | 由内容决定,无法直接设置 |
| 可包含的内容 | 块级元素、内联元素 | 仅内联元素或文本内容 |
| 典型用途 | 页面结构布局 | 文本内容修饰或小型内容展示 |
| CSS 支持 | 支持宽、高、内边距、边距等所有属性 | 边距和内边距仅水平方向生效 |
7. HTML5 新特性
- 语义化标签:
- 结构性标签:
<header>,<footer>,<nav>,<section>,<article>,<aside> - 多媒体标签:
<video>,<audio>,<source>
- 结构性标签:
- 表单控件:
- 日期、时间、颜色等输入类型:
<input type="date">,<input type="color"> - 内容 editable:
<div contenteditable="true">
- 日期、时间、颜色等输入类型:
- Web 存储:
localStorage,sessionStorage - Canvas:
<canvas> - 拖放 API:
<div draggable="true">
语义化标签的意义
- 提升代码可读性
- 改善 SEO(搜索引擎优化)
- 增强无障碍性(Accessibility)
- 便于浏览器解析和渲染
| 标签 | 描述 |
|---|---|
<header> | 定义页面或部分的头部,通常包含导航、标题。 |
<footer> | 定义页面或部分的尾部,通常包含版权声明等信息。 |
<article> | 表示一篇独立的内容(例如文章、博客条目)。 |
<section> | 表示页面中一个独立的主题内容区块。 |
<nav> | 定义导航链接区域。 |
<aside> | 表示与主要内容相关的补充信息(侧边栏)。 |
<main> | 定义文档的主要内容区。 |
<figure> | 表示独立的图像或图表,可以包含标题(<figcaption>)。 |
<time> | 表示时间(日期或具体时间点)。 |
8. 属性
- 常见全局属性:
- id:唯一标识符
- class:指定一个或多个类
- style:内联样式
- title:元素的提示信息
- data-:自定义数据属性
- lang:语言标识符
- 链接和表单属性:
- href:超链接目标地址
- action:表单提交的目标地址
- method:表单提交方法(GET/POST)
- target:超链接打开方式(_self, _blank, _parent, _top)
HTML 属性的作用是什么?
HTML 属性是 为标签提供附加信息 的关键工具。它们定义了元素的特性、行为或外观,能够改变或增强 HTML 标签的默认功能。
- 实现动态内容和交互:data-* 和 id 等属性可以与 JavaScript 配合,实现动态交互。
- 支持无障碍性:lang, alt, title 等属性帮助辅助技术(如屏幕阅读器)更好地呈现内容。
- SEO 优化:通过语义化属性(如 title, lang)帮助搜索引擎理解页面内容。
- 提升用户体验:placeholder、controls 等属性直接提升表单和媒体的可用性。
属性的默认值是在哪里设置的?浏览器自带的吗?
HTML 属性的默认值是由 浏览器的实现(浏览器内核) 决定的。浏览器会根据 HTML 标准规范 来定义某些属性的默认行为或值,并在渲染 HTML 元素时应用这些默认值。
- 浏览器如何设置默认值?
- 浏览器在渲染 HTML 页面时会执行以下步骤:
- 解析 HTML 文档
- 浏览器会逐行解析 HTML 元素,并根据 HTML 规范创建对应的 DOM 树节点。
- 如果某个属性没有明确指定,浏览器会自动为该属性应用默认值。
- 匹配内置行为
- 浏览器的内核为某些常见元素(如
<form>、<button>)设置了默认行为。
- 浏览器的内核为某些常见元素(如
- 渲染和显示
- 在 DOM 树基础上,浏览器结合默认样式表渲染页面内容。例如:
- 如果
<button>没有指定type,它会被视为 "submit"。
- 解析 HTML 文档
- 浏览器在渲染 HTML 页面时会执行以下步骤:
HTML 元素会自动加上默认属性吗?
HTML 元素的默认属性值 不会以显式的方式自动加到 HTML 中,但浏览器会按照 HTML 规范,在渲染时默认使用这些值。换句话说,这些默认值是浏览器解析和渲染时隐式应用的,而不是直接修改或补充到 HTML 源代码里。
- 默认值的存在是浏览器的解析逻辑,不会直接修改 HTML 文档。
- 在 DOM 中,这些默认值不会显式显示,除非开发者手动设置属性。
- 默认值的作用是保证未显式定义属性时,元素仍有标准行为和渲染效果。
9. 访问性和 SEO
- ARIA 属性:
role,aria-label,aria-hidden - SEO 优化:
- 语义化 HTML:使用合适的标签和结构
- 元标签:
<meta>标签中的关键词、描述等 - 标题优化:合理使用
<h1> - <h6>
- 键盘导航:确保表单和控件支持键盘操作
- 图像和链接的替代文本:使用
alt和title属性
爬虫是怎么个流程?它的原理是什么?
网络爬虫(Web Crawler),又称网页蜘蛛或机器人,是用于自动化访问和抓取网页内容的程序。其主要目标是遍历互联网上的网页,获取内容并存储到本地数据库或搜索引擎索引中。
- 爬虫的工作流程
- 初始化:爬虫从种子 URL(初始 URL)开始,通常由用户或管理员指定。
- URL 队列:爬虫将种子 URL 放入待抓取队列,并开始抓取。
- 抓取网页:爬虫从队列中取出一个 URL,发起 HTTP 请求获取网页内容。
- 解析内容:爬虫解析网页内容,提取有用的信息(如文本、链接、图片等)。
- 存储数据:将提取的信息存储到数据库或搜索引擎索引中。如果提取到新的 URL,则将其加入待抓取队列。
- 爬虫的核心原理
- URL 队列管理:爬虫通过管理待抓取和已抓取的 URL 队列,确保不会重复抓取同一网页,并按优先级抓取。
- 网页抓取:爬虫通过 HTTP 请求获取网页内容,解析 HTML、CSS 和 JavaScript,提取有用的信息。
- 数据存储:爬虫将提取的信息存储到数据库或搜索引擎索引中,以便后续查询和检索。
- 爬虫策略:爬虫采用不同的策略来决定抓取的顺序和范围,如深度优先、广度优先、优先级抓取等。
有什么反爬机制?
- IP 封禁:检测频繁访问并限制 IP。
- 验证码:验证用户身份。
- 动态内容:隐藏链接或使用动态渲染。
10. HTML 文档与网页配置
- 字符集声明:
<meta charset="UTF-8"> - Viewport 设置:
<meta name="viewport" content="width=device-width, initial-scale=1"> - 引入外部文件:
<link>(CSS),<script>(JS)